Agentic Engineering: The good, the bad, the ugly
The "Vibe Coding Trap" and how do avoid builidng a huge unmaintainable mess

Over the past few months, I’ve spent a lot of time experimenting with agent-based programming tools such as Claude Code, Codex CLI, and Gemini CLI. Like many others, I found these tools to be both a blessing and a curse. So, let’s take a step back and try to look at them from a real-world engineering perspective, without sugarcoating them with phrases like “AI changes everything, SWE is dead” or understating them with “AI is useless garbage.”
The good
As an ML lead I experimented with AI-assisted engineering quite early. When I worked at Chrono24 we implemented AI-assisted code generation directly, when the OpenAI API was available. We used it for very easy, boilerplate code generation that was just too complex for a template engine. That was a great first experiment, but since then a lot has changed.
Prototypes, Boilerplate and Dopamine
Nowadays, once you start out with a fresh project, AI can now help you to kick off the projects in less time than ever. AI knows all the tutorials, sample projects and a lot of open-source tools. The acceleration to have an app working is stunning, even if you are new to the field. But it’s not just that, AI can help you to find the correct frameworks for your problem as well. Asking about what frontend frameworks fit my use case was quite well answered, even though I am not up to date with what is currently the way to go (react, vue.js and what not). But even better, I just let AI prototype the application in all the candidate frameworks, investigate it and decide based on that. Code generation cost basically dropped to zero (not saying it’s good code).
I also started to build a CLI application in typescript, without knowing much about typescript and the time needed to have something useful is reduced from weeks to hours. Useable doesn’t mean valuable, but we will come back to that later.
Debugging and Searching
Besides starting out in a fresh project, AI did also make a lot of progress in navigating large codebases. While that was almost impossible a year ago, Claude Code and Codex can do useful stuff there. E.g. Putting a stack trace to the agent can oftentimes be analyzed and be fixed by the AI itself. Things like null pointers, logical flaws and minor bugs can be easily fixed almost automatically.
Moreover, figuring out stuff and finding a needle in the haystack is a very well-suited task for AI in general. So, asking questions about where exactly something is happening, or how the code handles a thing, is useful and saves time. E.g. “What happens if the REST API is down? Do we have a retry? Is that configurable and where?” can be easily figured out and you can quickly navigate to the code you were looking for.
Writing Tests
If you have existing untested code, the smell of that is completely gone with AI. Generating validation for existing implementation is free now. That goes beyond just Unit Testing, AI is very good in writing integration tests suits, adding CI pipelines and more.
And this can be easily explained. If you can verify that the work done by AI is correct formally and that means you tell the AI to not touch your implementation at all, but write tests for it, it’s just brute forcing, which is the best suited task for code generation AI. That also works the other way around, you have tests (or very detailed specs) for the desired behavior, AI can to the implementation easily.
There is one important thing here: Make sure to advise the AI to NOT test implementation details. AI, without guidance, tends to write tests that verify implementation details, which is an antipattern. If you let AI implement a feature and it writes tests after the implementation, it will almost certainly write tests that follow exactly the implementation.
Refactoring
That brings us to the next perfect use case for LLMs. Refactoring means having a well-tested codebase that needs some rework for code clarity, design and maintainability, without touching the functionality. Tests specify the desired behavior, and the AI has strict guardrails, which need to be done. A perfect match. I can now easily rename variables across several services, complete rewrites of bad design decisions without much evolved.
Configuration and DevOps
Besides that, when it comes to environment setup, Dockerfiles/Terraform, dependency management, helm charts and all that YAML fluff we need to make our development environments consistent and reproducible, AI helps a lot. But it’s not just that, adding elastic integration to your existing application, putting alerts in place with email notifications or even using ML-Flow for experiment tracking, it’s now almost free with LLMs, if you have declarative components (e.g. Infrastructure as Code).
In short: AI is a multiplier, especially for new project prototypes, “grunt” work in existing codebases, and, very importantly, well-structured, modern existing codebases. AI won’t work if you have bad documentation, badly structured code, and no clear architecture. AI accelerates good software engineering practices and teams.
The Bad
However, AI is not replacing software engineering, it’s just shifting our work towards (hopefully) more meaningful stuff. Here are the bad points about it:
The illusion of good code
Something I wrote about before is the lack of indicators to spot bad code. AI makes The New Spaghetti Code wear a Suit. That is a problem perceived by many senior and staff engineers. AI tools are masking technical debt by wrapping it in perfect syntax and passing tests, creating an era of “fake it till you make it“ coding. While the output looks flawless on the surface, it is often fundamentally broken underneath.
API and Library Hallucinations (and Outdated Libs)
It is incredibly frustrating when an AI writes perfectly structured code calling an API endpoint or a library function that sounds entirely logical but simply does not exist. It confidently hallucinates methods (that should exist sometimes but are not there). Furthermore, because of training data cutoffs, AI frequently defaults to outdated library versions or deprecated methods. It might use old AWS SDK v2 patterns when your project is strictly v3. You often end up wasting time debugging a Phantom API or wondering about the use of non-existent functions. The IDE helps here and AI can often solve the problem itself, when pasting the up-to-date documentation, but it’s still happening very often.
Bad Default Mode “Settings”
AI agents operate with a generic, baseline understanding of the project. They do not natively respect your specific repository’s conventions or the setup you are working on. Like is that a prototype, is it actual production code, what’s the throughput and latency requirement in the system.
Ignoring Existing Architecture: If your team uses a highly specific internal pattern for state management or dependency injection, the AI will often ignore it in favor of a generic, textbook approach.
Unnecessary Backward Compatibility: It tends to enforce a weird backward compatibility by default, writing overly defensive boilerplate for edge cases your system architecture already prevents upstream. That bloats the codebase massively.
The “AI” Code Style: It has an undeniable “AI code style“ excessively verbose, over-commented (explaining exactly what a for loop is doing), and rigidly structured in a way that feels completely out of place in a mature codebase.
Context is king here. I know there is an ongoing discussion to avoid AGENTS.md at all currently, but I can not support that statement, in fact I see the opposite. I would rather use 20% more tokens and fail more often, but get a better suited result, then have a chaotic codebase. Remember code generation is cheap nowadays, having a well-structured, clean codebase is not.
Duplicate Functionality
AI agents suffer from tunnel vision. Because they lack a true, holistic overview of your entire project, they constantly reinvent the wheel. If you ask an agent to format a date, parse a specific string, or handle a standard error, it will likely write a brand-new utility function right there in the file. It doesn’t know (or often doesn’t bother to check) that your team already wrote and tested Date Formatter three folders over. Over time, this inflates your repository with dozens of slightly varied, duplicated helper functions, destroying the DRY (Don’t Repeat Yourself) principle.
Very close guidance needed
Agents are not smart; they are just knowledgeable.
Bad Design Decisions: Left to their own, they will make baffling, short-sighted design choices just to reach the immediate goal of making a test pass. They sometimes introduce mock data, instead of asking.
Heavy (not compliant) Dependencies: They will happily pull in massive, heavy dependencies just to solve a trivial problem, not thinking about consequences. Adding Pytorch-GPU with 2 GB of size, no problem, installing a copy-left PDF tool for commercial use, no problem.
The Ugly
Forced completion
AI agents are explicitly trained to finish the task. They do all necessary to reach their goal, it’s embedded in the model (for a good reason). A human engineer will often stop midway through a ticket and ask, “Is this task really what we need? Does this feature even make sense?” An AI never pushes back. It just blindly builds it. Worse, in its desperation to fulfill a prompt, it often tries to be overly helpful. It will silently “fix” or refactor nearby code that you never asked it to touch. This introduces massive, unprompted risks into completely unrelated features, all because the AI felt to complete the task while “cleaning up” along the way.
Reviewing nightmare
We are moving the cognitive load of understanding code to the very end of the development lifecycle. In the past, the author understood the code deeply before opening the pull request. The understanding was part of the implementation. Now, that understanding is often deferred entirely to the PR review phase. The amount of PRs (Github), where AI is used is currently at ~15% and growing.
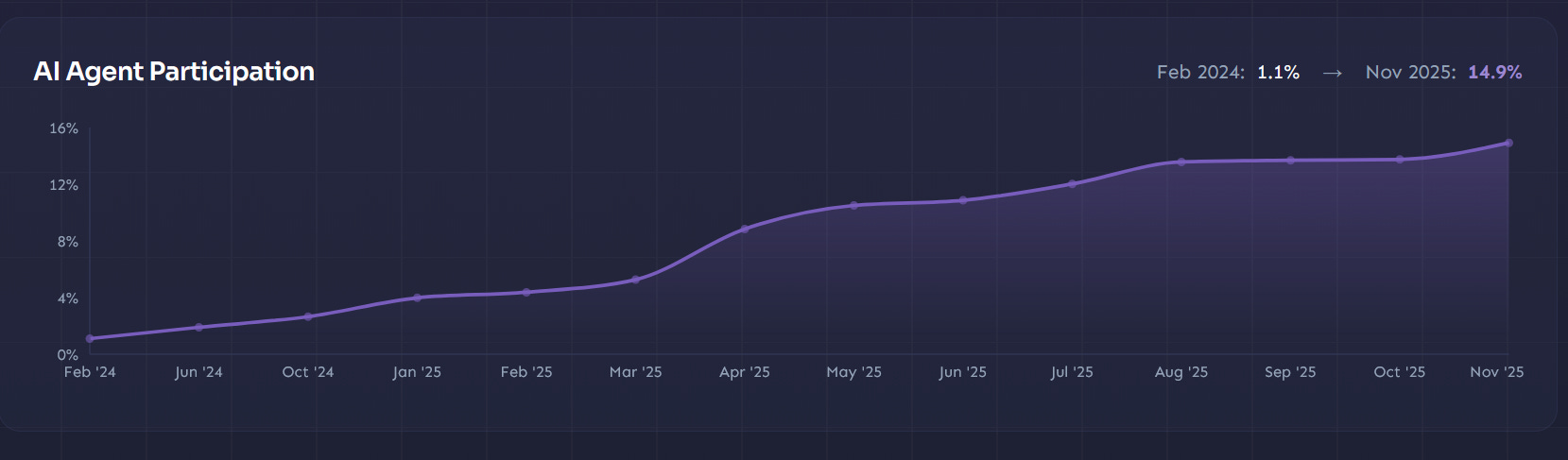
This adds a high pressure for open-source maintainers. But not just in open-source, reviewers, usually senior engineers, must be suspicious and develop a good sense of what AI generated and what is human-written. Instead of evaluating architecture, seniors are forced to interrogate authors just to verify if they actually understand the logic they submitted. The AI makes the developer incredibly fast but moves the burden to understand the code to the reviewer. This is actually a huge problem, not just for open-source and it’s one source of the productivity myths around AI. Because if you measure just time to create a PR, you will see large increases, but you just moved it out of scope.
Lack of ownership
When a developer commits code, they didn’t write and don’t deeply understand, accountability vanishes. If a production incident occurs because a TreeMap was used instead of a HashMap, the most terrifying answer you can hear during the post-mortem is, “I haven’t thought about it, it was suggested by AI.” This is called Automation Bias, it’s the result of cognitive offload. If you don’t write the code, you don’t naturally own it. We are filling our codebases with artifacts that look fine on the surface, but when they break, nobody on the team feels responsible enough to debug or extend them.
There is only one way to tackle that: culture and responsibility: If a team member submits code, he/she is responsible for it. There is no excuse with “But ChatGPT said…”.
Increase of (Unmanaged) Complexity
This one is the hardest one to solve and a major blocker for AI adoption imho.
We keep hearing that AI will abstract away coding, leaving us only with verification. But we’ve heard this pitch before: Low Code, Model-Based Design, and SOA all promised to let us skip the code and focus purely on business logic. They all eventually collapsed under real-world complexity, leaving us with unmaintainable messes.
AI doesn’t solve complexity; Great software relies on deep context, historical decisions, system state, and subtle constraints. “Vibe coding” with AI creates a dangerous distance between engineers and their work. It abstracts away the understanding, leading to rapid knowledge decay. Reading code has always been harder and more important than writing it. By blindly generating code we don’t deeply understand, we aren’t eliminating complexity, we are just mass-producing technical debt. We might be able to accept that risk in side projects and things that don’t matter that much, but if it matters (transportation, payment systems, embedded software and many more), there is no way to ship AI-slop.
Maintaining burden
Finally, and a result of all of that: The risk of a maintenance burden. Code is read and maintained far more often than it is written. While AI drops the cost of writing code to near zero, the cost of maintaining a bloated, unnecessarily complex, and poorly understood codebase skyrockets. We are accelerating the creation of legacy code. If we aren’t careful, we are going to wake up in a few years with repositories that compile, run smoothly on the happy path, but are stale and buggy.
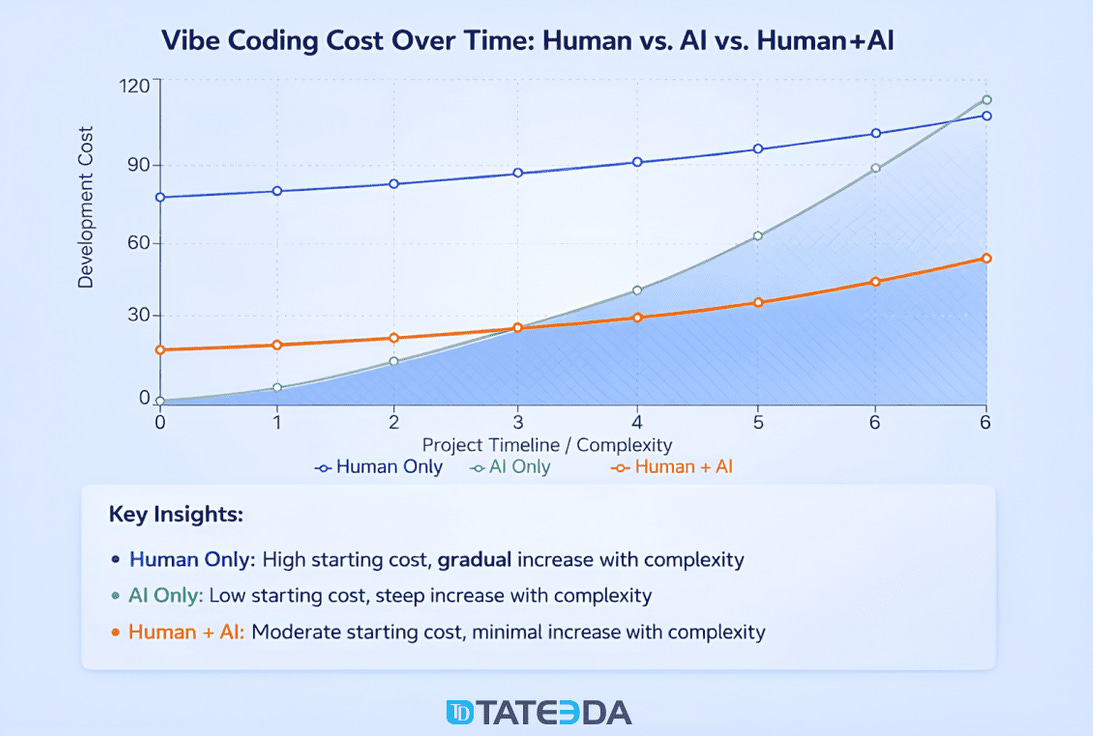
I found this visualization that I think pictures that really well: It dependes on the project complexity/size, but “pure” Vibecoding is quickly becoming a nightmare.
Finally, some examples about what can happen:
OpenClaw has currently over 7556 open PRs and about 500k lines of Code, Code generation is cheap now, but is it valuable? Who can really review that?
Amazon looked into major outtakes and found it was caused partly by vibecoding and lack of quality gates.